


Science & Tech
Visual forensics that can detect fake text

Courtesy of SEAS
Researchers develop a method to identify computer-generated content
In a time of deepfakes and AI equipped with far-too-human natural-language, researchers at the Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) and IBM Research asked: How can we help people detect AI-generated text?
That question led Sebastian Gehrmann, a Ph.D. candidate at the Graduate School of Arts and Sciences, and Hendrik Strobelt, a researcher at IBM, to develop a statistical method, along with an open-access interactive tool, to differentiate language generated by code from human speech.
Natural-language generators are trained on tens of millions of online texts and mimic human language by predicting the words that most often follow one another. For example, the words “have,” “am,” and “was” are statically most likely to come after the word “I”.
Using that idea, Gehrmann and Strobelt developed a method that, instead of flagging errors in text, identifies text that is too predictable.
“The idea we had is that as models get better and better, they go from definitely worse than humans, which is detectable, to as good as or better than humans, which may be hard to detect with conventional approaches,” said Gehrmann.
“Before, you could tell by all the mistakes that text was machine-generated,” said Strobelt. “Now, it’s no longer the mistakes but rather the use of highly probable (and somewhat boring) words that call out machine-generated text. With this tool, humans and AI can work together to detect fake text.”
“This research is targeted at giving humans more information so that they can make an informed decision about what’s real and what’s fake.”
Sebastian Gehrmann
Gehrmann and Strobelt will present their research, which was co-authored by Alexander Rush, an associate in computer science at SEAS, at the Association for Computational Linguistics conference Sunday through Thursday.
Gehrmann and Strobelt’s method, known as GLTR, is based on a model trained on 45 million texts from websites — the public version of the OpenAI model, GPT-2. Because it uses GPT-2 to detect generated text, GLTR works best against GPT-2, but it does well against other models, too.
Here’s how it works:
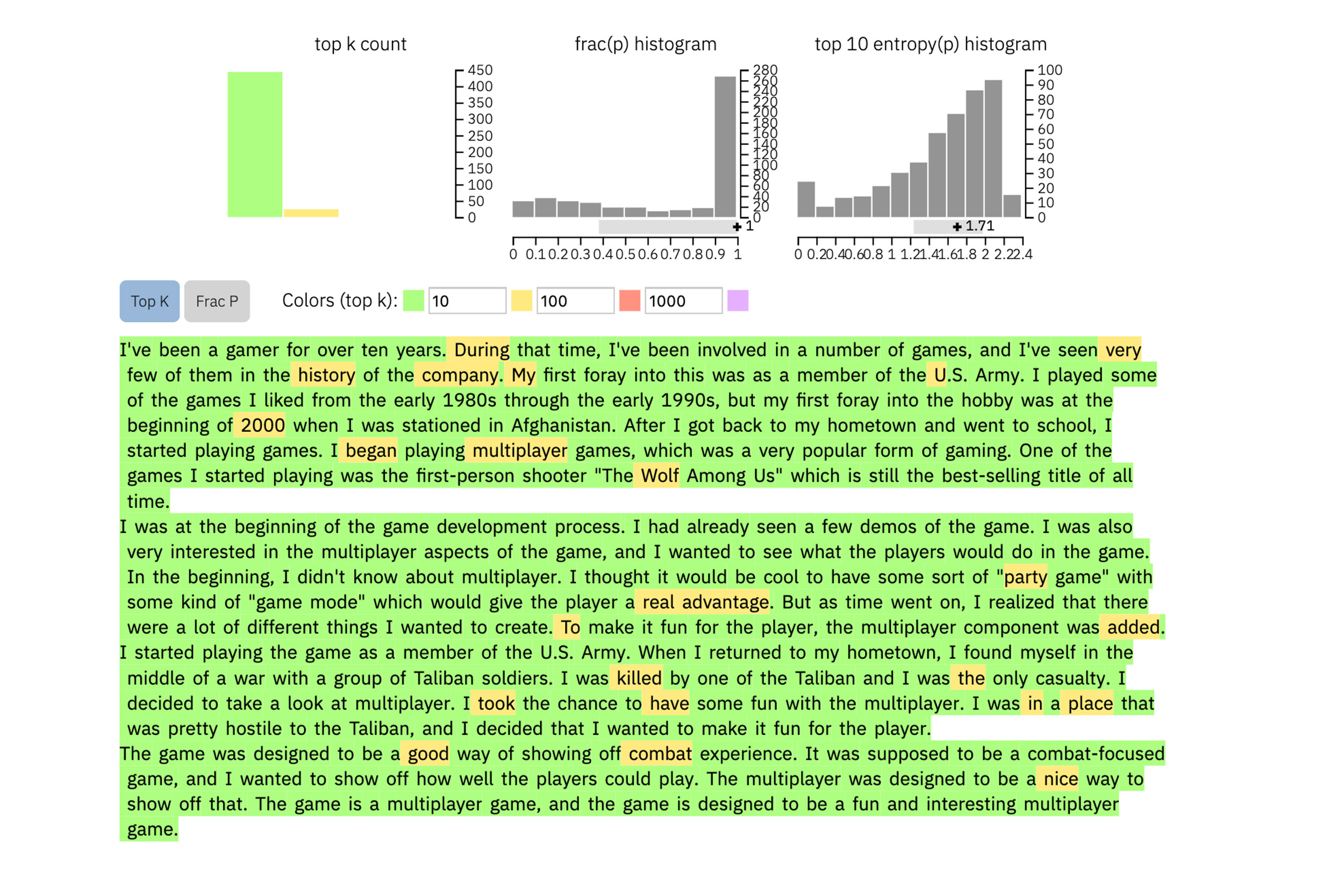
Users enter a passage of text into the tool, which highlights each word in green, yellow, red, or purple, each color signifying the predictability of the word in the context of what it follows. Green means the word was very predictable; yellow, moderately predicable; red not very predictable; and purple means the model wouldn’t have predicted the word at all.
So, a paragraph of text generated by GPT-2 will look like this:


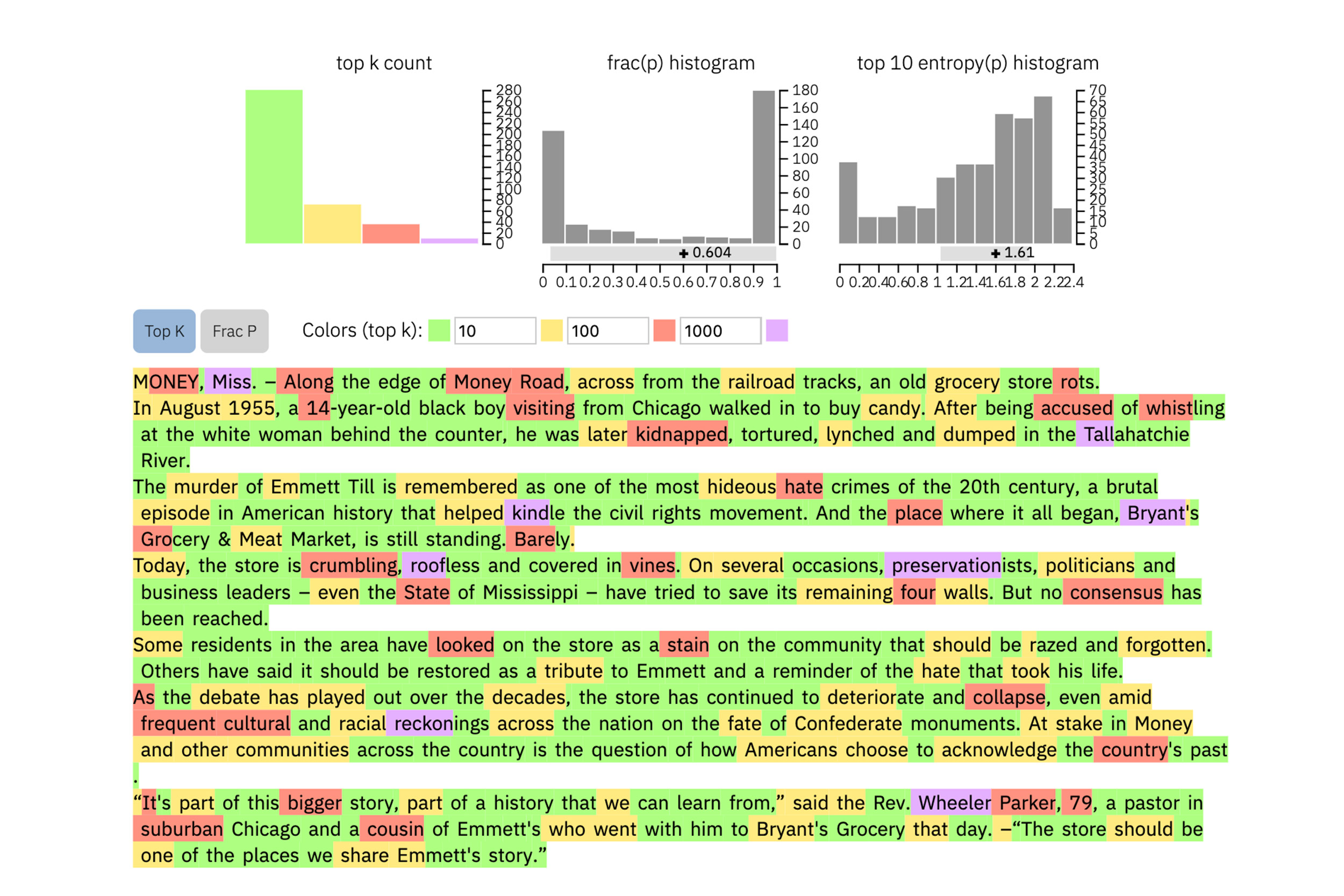
To compare, this is a real New York Times article:
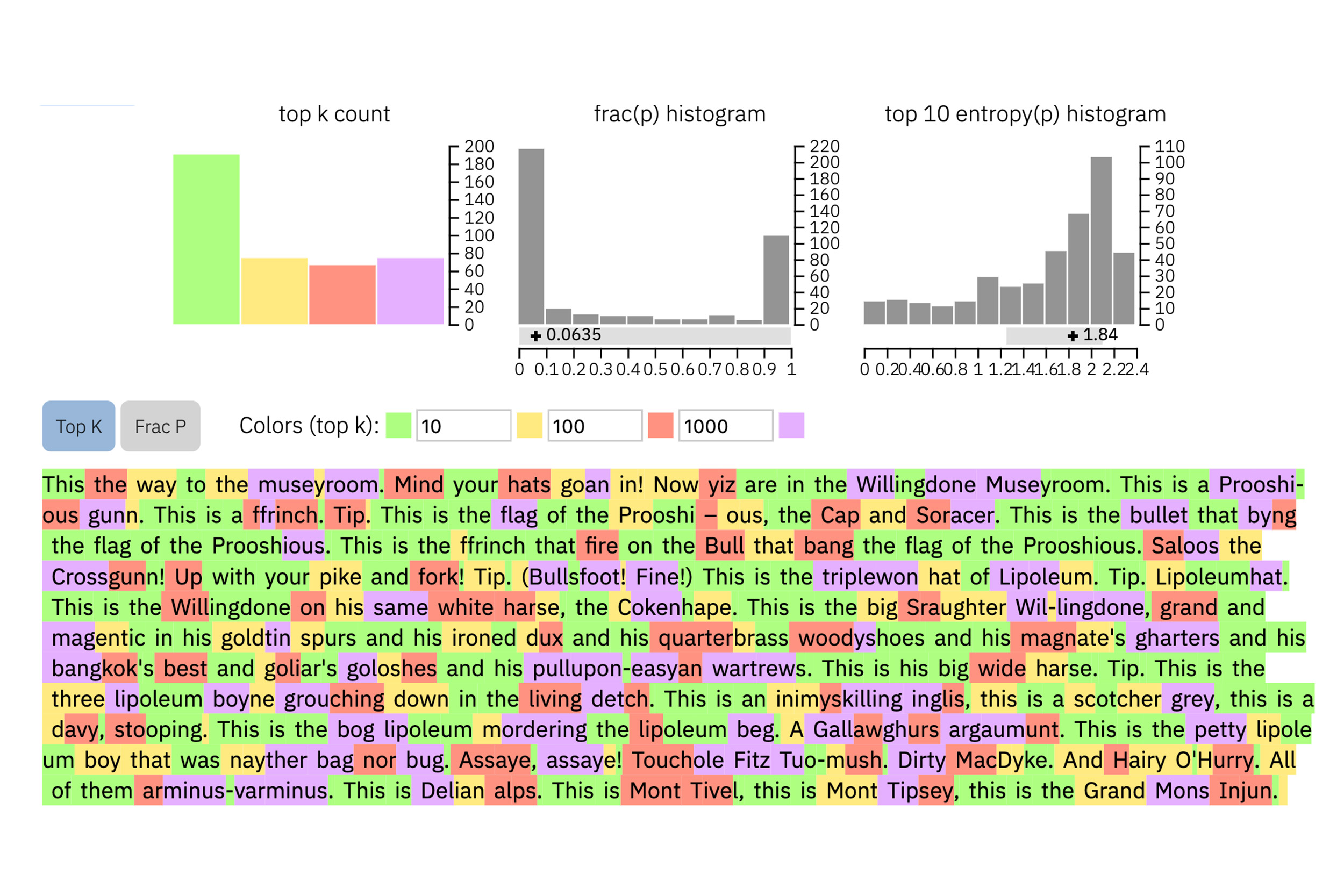
And this is an excerpt from arguably the most unpredictable text ever written by a human, James Joyce’s “Finnegans Wake”:
The method isn’t meant to replace humans in identifying fake texts, but to support human intuition and understanding. The researchers tested the model with a group of undergraduates in an SEAS computer science class. Without the model, the students could identify about 50 percent of AI-generated text. With the color overlay, they identified 72 percent.
Gehrmann and Strobelt say that with a little training and experience with the program, the percentage could get even better.
“Our goal is to create human and AI collaboration systems,” said Gehrmann. “This research is targeted at giving humans more information so that they can make an informed decision about what’s real and what’s fake.”





